
SEOとGEOはなぜ噛み合わないのか? AI検索をIndex・Retrieval・Synthesisで読み解く
最終更新日: 2026.03.16
この記事でわかること
1.SEOとGEOの対立は、本質的な思想の違いではなく、見ている工程の違いにすぎないこと
2.AI検索では、順位よりも「どの情報が候補となり、どのように最終回答として生成されるか」が重要になること
3.Rand Fishkinの実験が示した回答の揺れは、Synthesisにおける確率的生成として理解できること
AI検索をめぐる議論が、少しずつ熱を帯びています。
「GEOはまだ早い」
「GEOはSEOの延長にすぎない」
「GEOという言葉自体が好きではない」
「SEOはオワコンだ」
どの意見にも一理あります。ただ、議論を追っていると、そもそも同じ話をしていないのではないか、と感じることがあります。
ある人は「見つかるかどうか」を語っている。
ある人は「呼び出されるかどうか」を語っている。
そして別の人は、「最終的にどう答えになるのか」を語っている。
同じAI検索を論じているようで、実際には見ている工程が違う。そのズレが、SEOとGEOの対立を必要以上に大きく見せているのではないでしょうか。この問いを考えるうえで、Search Engine Landに掲載されたJason Barnardの記事Rand Fishkin proved AI recommendations are inconsistent – here’s why and how to fix itは、よい出発点になります。
1. Jason Barnardが整理したConfidenceという視点
上述のJason Barnardの記事は、Rand Fishkinの実験を受けて書かれたものです。
Rand Fishkinが行ったのは、AIにブランド推薦を繰り返し尋ね、その出力の安定性を検証するという実験でした。その結果、同じ質問をしても提示されるブランドリストは毎回異なり、順位もほとんど一致しないことが明らかになりました。
この結果から見えてくるのは、AI検索では従来の検索のような固定的な順位という考え方がそのまま成立しにくいということです。ただし、完全にランダムというわけでもありません。あるブランドは高頻度で出現し、あるブランドはほとんど出ないという偏りも確認されています。つまり、候補として呼び出されやすいブランドとそうでないブランドの差は存在しているのです。
この実験に対して、Jason Barnardは「AIはRecommendation Engineではなく、Confidence Engineである」という視点を提示しました。ここで言うConfidenceとは、AIが自分の回答にどれだけ確信を持っているかという意味ではありません。情報がどれだけ安定して候補として扱われやすいかという、構造的な確からしさを指しています。
その形成過程を、彼はDSCRI-ARGDW(Discovered, Selected, Crawled, Rendered, Indexed, Annotated, Recruited, Grounded, Displayed, Won)というパイプラインで整理しました。
情報は、まず発見され、収集され、意味的に整理され、文脈に組み込まれ、最終的に推薦として表示される。そしてその過程のどこかで整合性が揺らげば、最終的な出現確率も下がる。DSCRI-ARGDWは、情報に対する信頼がどのように形成され、どのように蓄積していくのかというプロセスを理解するうえで非常に有効なモデルです。
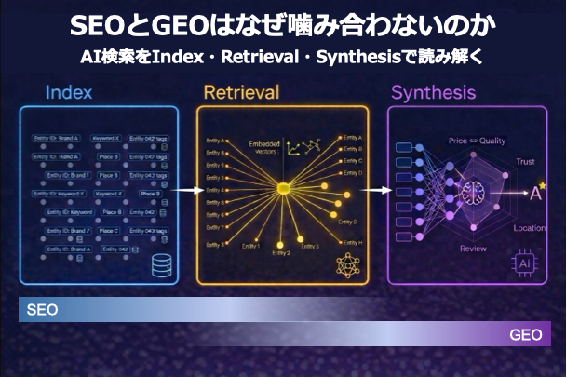
2. AI検索を三つの工程で読み解く
DSCRI-ARGDWは「信頼がどのように形成されるか」を精緻に分解したモデルです。しかしその精緻さゆえに、どこが現在の議論の焦点なのかが見えにくくなっています。そこで本稿では、このプロセスを Index・Retrieval・Synthesis の三つの工程に抽象化して捉えてみたいと思います。こうすることで、SEOかGEOかというラベルの違いではなく、「どの工程を主な設計対象として見ているのか」という構造の違いが見えやすくなります。
Index(存在が確立される段階)
Indexは、情報がシステムの中に取り込まれ、記憶される段階です。クロールされたコンテンツはレンダリングを経て構造化され、検索エンジンやAIシステムが扱える形で保存されます。さらにこの工程では、Annotationによって「何について書かれた情報なのか」「どのエンティティに属するのか」「どの文脈で利用されうるのか」といった意味的な整理も行われます。こうしてコンテンツは単なるページではなく、意味的に整理された知識としてシステムに取り込まれます。DSCRI-ARGDWで言えば、Discovered, Selected, Crawled, Rendered, Indexed, Annotatedの領域がここに対応します。
Retrieval(文脈に呼び出される段階)
存在しているだけでは、十分ではありません。Retrievalは、特定の意図や文脈のもとで、その存在が呼び出される段階です。意味的に関連があると判断され、再利用可能な候補として浮上するかどうかがここで決まります。つまり、あるブランドや情報が回答候補になりうるかは、この工程に大きく左右されます。DSCRI-ARGDWでは、Recruited, Groundedが対応します。
Synthesis(意味が統合され、回答が生成される段階)
そして最後に、Synthesisがあります。Retrievalされた複数の情報は、そのまま一覧として提示されるわけではありません。AIはそれらをもとに、文としてつなぎ、要点をまとめ、ひとつの答えとして出力します。
ここで重要なのは、Synthesisが単なる情報の表示ではなく、候補群をもとにした確率的な生成過程だということです。候補があるからといって、毎回まったく同じ形で答えが出るわけではありません。どの候補を前面に出すか、どの順序で言及するか、どの表現でまとめるか、どこを省略するか。こうした最終出力は、Synthesisの局面で確率的に決まります。
Rand Fishkinの実験が示した「同じ質問でも回答が揺れる」という現象を理解するうえで、重要なのがこの工程です。AIは、Indexされた情報をRetrievalで候補化し、その候補をSynthesisで最終的な答えにまとめる。問題は、この最後の工程が確率的な生成であるという点にあります。
DSCRI-ARGDWで言えば、Displayed, Wonが形式的にはこの工程に関わります。しかし本稿ではこれを「どのように表示されるか」という結果の記述ではなく、「どのように答えが生成されるか」という局面として捉え直したいと思います。この対応関係を整理すると、次のようになります。
Index・Retrieval・SynthesisとDSCRI-ARGDWの対応関係
|
工程 |
主な役割 |
DSCRI-ARGDW対応 |
|
Index |
存在の確立 |
Discovered〜Annotated |
|
Retrieval |
文脈への呼び出し |
Recruited, Grounded |
|
Synthesis |
意味の統合と回答生成 |
Displayed, Won |
この整理から見えてくるのは、DSCRI-ARGDWがIndexとRetrievalを厚く扱う一方で、Synthesisは相対的に圧縮されているということです。比較的Index、Retrieval寄りのモデルだとも言えます。
3. Rand Fishkinの実験は何を示していたのか
ここで、Rand Fishkinの実験にもう一度立ち返ってみます。この実験が示した揺れを、単なる不安定さとしてではなく、安定した候補群の上に生じるSynthesisの揺れとして読み替えること。これが本稿の核心です。
彼の実験が示したのは、同じ質問を繰り返しても、AIの回答は固定されないということでした。提示されるブランドの顔ぶれが少しずつ変わり、順位も安定しない。従来の検索に慣れていると、この不安定さは奇妙に見えます。しかし、この揺れを候補の完全な無秩序ではなく、安定した候補群の上に生じるSynthesisの揺れとして捉えるなら、この現象はかなり自然に理解できます。
AIは、毎回ゼロから完全にランダムで答えているわけではありません。IndexとRetrievalによって、一定の候補群や意味的に近い情報が呼び出される。そのため、よく出てくるブランドとそうでないブランドには偏りが生まれます。ここにJason Barnardの言うConfidenceの効いている部分があります。
ただし、その候補群がある程度安定していたとしても、最後にそれをどうまとめるかは別問題です。どの候補を先に出すか。どの表現で紹介するか。どこまで言及するか。何を省略するか。こうした最終的な出力の形は、Synthesisの局面で確率的に決まります。これは、生成AIに同じプロンプトで文章作成を依頼しても、毎回少しずつ異なる文章が生成される現象を思い浮かべると理解しやすいでしょう。
つまり、Rand Fishkinの実験が示した揺れは、必ずしも検索品質が低いということを意味しません。むしろ、AI検索が固定順位の提示ではなく、候補をもとにした生成であることの表れだと理解した方がよいのではないでしょうか。
この視点に立つと、「AIの推薦は一貫していないから意味がない」という見方も少し変わってきます。たしかに、単発の出力だけを見て順位を測ろうとすれば、意味は取りにくいでしょう。しかし、繰り返しの中でどのブランドがどれくらい安定して候補化され、どれくらい繰り返し答えに現れるかを見るなら、そこには分布としての傾向が現れます。
4. なぜ議論がすれ違うのか
ここまでの整理を踏まえると、現在の議論が噛み合いにくい理由も見えてきます。
「GEOはSEOの延長にすぎない」という主張は、IndexとRetrievalを中心に見ている立場からすれば自然です。情報の発見、構造化、意味づけ、呼び出されやすさの設計。この領域においては、確かに連続性があります。
「GEOはまだ早い」という意見も理解できます。トラフィックの現実を見れば、IndexとRetrievalの最適化が今も重要であることは変わりません。
一方で、「SEOはオワコンだ」という主張は、Synthesisの変化を強く見ている立場から生まれています。従来はユーザーが行っていた比較や要約の一部がAIに移り、その最終出力が確率的に生成されるようになった。そう考えれば、設計対象が広がったと感じるのも無理はありません。
そして、「GEOという言葉が好きではない」という感覚も理解できます。工程の一部を切り出して新しいラベルを付けることに、過剰な断絶を感じるからでしょう。
まとめ:SEOとGEOの視点を三工程で統合する
AI検索とは、IndexとRetrievalによって形成された候補群の中から、Synthesisによって最終回答が生成されるプロセスです。
SEOとGEOの違いは、この三工程のどこを主戦場と見るかの違いにすぎません。IndexとRetrievalの最適化は今も不可欠です。しかしAI検索の時代には、Synthesisの局面、つまりRetrievalされた情報がどのように最終回答へとまとめられるのかという視点が加わります。その意味で、GEOはSEOの否定ではなく、三工程の最後までを設計対象に広げた思考だと言えるでしょう。
なお、本稿では論点を絞るために、Synthesisを主に「確率的な回答生成」という観点から扱いました。この確率的な回答生成という視点については、「AI Visibilityに『順位』はない。Rand Fishkinの実験が示したGEOの本質とアトラクターという考え方」という記事で詳しく整理しています。
さらにSynthesisでは、単に答えが揺れるだけでなく、どの観点から語られるか、何が重視されるかといった統合のされ方も変化します。この点については、「意味空間で戦うということ。アンカー構築というGEOの設計思想」という記事で掘り下げています。
Jason Barnardのモデルは、AI検索の工程を理解するうえで非常に有益です。そこに、SynthesisにおけるAIの確率分布的な振る舞いまで加えて考えることで、SEOとGEOは対立概念ではなく、同じプロセスの異なる焦点としてつながって見えてきます。そう捉えたとき、インデックスされやすい情報設計、呼び出されやすい文脈設計、そして最終回答に残りやすい意味設計をどう統合して考えるかという戦略が、より立てやすくなるのではないでしょうか。
執筆:渡辺一男
CONTENT MARKETING LAB ファウンダー
※本記事は執筆及び画像作成にあたり、生成AIを利用しています。
NEWS LETTERをお届けします!

コンテンツマーケティングラボの最新情報を、
定期的にEメールでまとめて、お知らせします
当月の更新情報を翌月初にお届けします。
(購読すると弊社の書籍発売イベントの特典資料をダウンロードできます)
※更新情報をすぐにSNSで受け取りたい方はこちら
![]()
![]()



.png)
